Android 内存优化方法
更新日期:
统计方法
做优化相关的工作,最重要的就是要有可以量化的指标。所以我们先要知道哪些可以衡量系统占用内存的方法和工具。结合自身工作的一些经验和网上的一些资料,下面先介绍一些查看内存占用情况的方法和工具:
dumpsys meminfo
dumpsys meminfo 是 Android 中最常用的查看内存的一个命令。它是 AMS(ActivityManagerService)中一个 binder 接口,具体源码见参考资料,它会显示当前的内存情况:
|
|
上面是一个 512M Android 10 设备中的 dumpsys meminfo 的输出。
Total RAM:
这个数值是当前系统的所有内存大小。它是读取 /proc/meminfo 节点中的 MemTotal 获取的(/proc/meminfo 这个节点的信息我们后面再说)。它一般并不等于机器的物理内存大小,例如这里物理内存是 512M。那是因为 linux kernel 都会有预留内存(reserved),这个后面再说。物理内存 - kernel reserved = 系统实际内存总和。
Free RAM:
这个数值是当前系统可用内存大小。它是后面括号内那3项之和:
(1).cached pss: 是 Total PSS by OOM adjustment 里面 Cached 分类的总和。OOM score 是 Android 根据进程的类型给 lmk 打的分数,lmk 从高分开始回收进程。其中 Cached 的是 OOM 900 以上的,一般都是切到后台的进程,表示可以随时回收。Rss(resident set size)表示常驻内存的大小,但是由于不同的进程之间会共享内存,所以用 Rss 表示进程内存会偏大。而 Pss(Proportional Set Size)把共享内存的 Rss 进行了平均分摊,所以一般使用 Pss 来表示进程的内存大小。而这里把 OOM 900 以上的所有进程的 Pss 算做 free 内存,我认为并不准确。Android 的应该是认为 OOM 900 以上的进程能随时被 lmk 回收,所以认为这部分可以算作 free 内存。但是其实这些进程中包含进程的已经申请并且分配了的内存,所以这个算法我认为并不能很好的代表 free 内存。这也是我并不推荐参考这个 Free RAM 数值来衡量当前系统的可用内存的原因。
(2).cached kernel: 是 /proc/meminfo 中下面几项计算出来的: Buffers + Cached + SReclaimable - Mapped。
Buffers: 是 kernel 中块设备(block)申请的内存大小。
Cached: 这部分是文件缓存,例如进程加载的 so,jar,ttf,dex 等资源。它们的原始数据都在磁盘中,在内存紧缺的时候可以很方便将占用的内存交换出来使用。
SReclaimable: 是 Slab 中的可回收的部分。Slab 是 linux 中的一种内存分配机制。一般都是 kernel 模块使用的。在 Android 7 的时候 dumpsys meminfo 还是将所有的 Slab 计算到 Free RAM 中的,在 10 中改成可以回收的部分了。
Mapped: 是 Cached 中已经被 mapped 的部分。Cached 中有一部分是被 unmapped 的,但是没有马上释放。可以理解 Mapped 就是进程中的一些文件资源已经被 load 进内存里面的。
(3).free: 是 /proc/meminfo 下的 MemFree。
从上面的统计内容来看,和一般 linux 理解的 free RAM 并不一样,一般的 linux 认为 Free RAM = free + Cached。也就是说 Cached 在内存充足的情况,缓存了进程运行所需要的资源,能加快进程的运行(对于app启动速度尤为明显);当内存不足的情况,可以快速的交换出来。linux 认为这可以算作可用内存,所以 linux 的 Cached 一般都比较大,真正的 free 内存都很少。而 dumpsys meminfo 则认为 lmk 可以随时回收的 Pss 是可用内存,而 load 进内存的文件 Cached 则不算。以我目前的认知,我认为 free + Cached 代表 Free RAM 能有更好的体验。并且 google 的 cts 测试统计可用内存也是按 free + Cached 统计的,但是某些下游客户比较执着于 dumpsys meminfo 的 Free RAM 统计算法。
Used RAM:
这个数值是当前系统已经内存的大小。它也是后面括号内那2项之和:
(1).used pss: 是 Total PSS by OOM adjustment 除了 Cached 分类之外的进程的 Pss 之和。
(2).kernel: 分2部分:第一部分是 /proc/meminfo 中: Shmem + SUnreclaim+ PageTables + KernelStack:
Shmem: Shared memory 即 kernel 中的共享内存,tmpfs 也会被统计为 Shmem。
SUnreclaim: Slab 中的不可回收部分。
PageTables: kernel 中用来转化虚拟地址和物理地址的。
KernelStack: 每个用户线程都会在 kernel 有个内核栈(kernel stack)。kernel stack 虽然属于用户态线程,但是用户态无法访问,只有 syscall、异常等进入到内核态才会调用到。所以这部分内存是内核代码使用的。
第二部分是 VM_ALLOC_USED,它是 kernel 中的模块通过 vmalloc 函数申请的内存,通过统计 /proc/vmallocinfo 中 “pages=” 数值之和得到(注意这里统计的单位是页面,一般Android上跑的 linux 一个页面都是 4Kb)。
这部分,kernel 统计还算合理,used pss 把 OOM 900 以上的进程的 Pss 全部剔除(前面算作 Free RAM 了),理由还是和前面一样,我认为是不合理的。
ZRAM:
zram 是 linux 的一项内存压缩技术,Android 里面用来当 Swap 用。当配置开启了 Zram,AMS 会把一些优先级低线程标记为可以放入 Swap 分区(例如说一些 Cached 进程)。这个 Swap 是基于内存的(Zram 支持写回磁盘,但是Android没支持),线程数据放入 Swap 的时候,会进行压缩(可以配置压缩算法),然后把之前占用的内存就可以给其他线程使用了。当再次使用这个线程数据的时候,再从 Swap 解压换回正常内存。这样能在小内存设备上挤出更多的内存空间给前台进程使用。
(1).22,368K physical used for: 是读取 /sys/block/zram0/mm_stat 统计的。mm_stat 一共有8个数值,含义可以参看参考资料里面的 kernel 官方文档。这里读取的是第三个数值,也就是 mem_used_total。这里代表是实际物理内存使用的大小(经过压缩算法)。
(2).68,664K in swap: 是 /proc/meminfo 里面 SwapTotal - SwapFree。代表 swap 里存放实际内存的大小(解压之后的) 。
(3).364,516K total swap: 是 /proc/meminfo 里面的 SwapTotal。可以由方案配置。A50 配置的 zram size 是整个内存的 75% (在方案下的 fstab.sun8iw15p1 里有配置),我截图的是 512M 的(整个内存是除去预留内存的实际可用内存),486,028k * 0.75 = 364, 521k,差不多。
上面整体来看,就是使用了 22M(22,368K)内存,压缩存放了 67M(68,664K)的数据,压缩比例大概是 67% 。
Lost RAM:
这一项其实没什么实际意义,它是: Total RAM - (totalPss - totalSwapPss) - free - cached kernel - kernel - zram total:
(1).TotalPss - totalSwapPss: totalPss 就是上面所有进程 Pss 之和。但是为什么要减去 totalSwapPss。每个进程的 SwapPss 在 /proc/pid/smaps 里面可以统计到(smaps 里面每一段 vma 里面都有 SwapPss)。拿来举例的设备是开启了 ZRAM 的,dumpsys meminfo 统计进程的 Pss 是计算了 swapPss 在里面的。所以其实按真正内存使用来看,是要减去 SwapPss。
(2).free: Free RAM 里面的 free
(3).cached kernel: Free RAM 里面的 cached kernel
(4).kerenl: Used RAM 里面的 kernel
(5).zram total: ZRAM 里面的 physical used for
其实上面的公式可以简单化为: Lost RAM = Total RAM - Free RAM - Used RAM - zram physical used + totalSwapPss 。totalSwapPss 从统计原理来看,应该等于 ZRAM 项里面的 “in swap” ,但是计算了一下发现有点偏差。用 totalPss 去减 procrank 统计的 totalPss(procrank 进程的 pss 是直接通过 /proc/pid/map 来统计的,没有加 swapPss,所以比 dumpsys meminfo 的小一些)来计算 totalSwapPss 也还是有点偏差,有可能是前面2次命令的时间间隔带来的进程数据统计偏差,也有可能是本来这么算就有点偏差。不过用 dumpsys meminfo 的 totalPss - procrank 的 totalPss 的偏差会比较小。所以我偏向于用这种方式计算 totalSwapPss (当然也可以在自己在 AMS 的源码里面打 totalSwapTotal 打印出来,这样就没偏差了)。
Tuning:
这里的值都是一些属性配置的值:
(1).128: dalvik.vm.heapgrowthlimit属性取值,单位为MB
(2).large: dalvik.vm.heapsize属性取值,单位为MB
(3).oom: ProcessList中 mOomMinFree 数组最后一个元素取值
(4).restore limit: ProcessList中 mCachedRestoreLevel 变量取值,原生设计是 oom 的 1/3
(5).low-ram: ro.config.low_ram=true 时判断显示 low-ram,ro.config.low_ram=false 且 config_avoidGfxAccel 为 false 时显示 high-end-gfx
dumpsys meminfo pid:
不加 pid 参数是统计整个系统所有进程的内存信息,如果后面接 pid 可以详细显示单个进程的内存信息。例如说下面这个是 dump systemui 的 pid(3382):
|
|
你会发现就算只间隔了2个命令的时间,详细统计出来的 Pss 都会和整体统计的有些小差别。因为程序每时每刻都在运行变化,所有总会优点小差别。
单独 dump pid 和统计方法和整体 dump 是一样的,就是说整理 dump 里面所有进程的 Pss 的统计之和就是单独 dump 的方法统计出来的,只是整体的只是取了 Pss 而已。是通过统计 /proc/pid/smaps 里面的项目得到上面这些信息(统计核心代码在 android_os_Debug.cpp 里面的 android_os_Debug_getDirtyPagesPid() 和 load_maps())。详细说明见 /proc/pid/smaps(/proc/pid/maps)章节说明。
(1). 我们先来说横着的列:
Pss Total: /proc/pid/smaps vma 里面 Pss 之和
Private Dirty: /proc/pid/smaps vma 里面 Private_Dirty 之和
Private Clean: /proc/pid/smaps vma 里面 Private_Clean 之和
SwapPss Dirty: /proc/pid/smaps vma 里面 SwapPss 之和(这是开了 Zram 的,如果没开就是 Swap 之和,同时显示会变为 Swap Dirty)
Heap Size: Native Heap 是 mallinfo() 里面 usmblks 的值。mallinof() 这个是一个 glic 函数,用来获取当前 native heap 的信息,返回的是一个结构体,里面的字段可以 man mallinfo 查看。usmblks 是 heap 能申请的最大值。Dalvik Heap 是 java 类 Runtime 里面的 totalMemory() 函数获取的,是当前虚拟机的 heap 大小,这值会动态调整,初始大小和调整策略由 dalvik.vm.heapgrowthlimit 和 dalvik.vm.heapsize 属性控制(这里不展开说)。
Heap Alloc: Native Heap 是 mallinfo() 里面 uordblks 的值,表示当前 native heap 已经申请的内存大小。Dalvik Heap 是 Runtime 里面 totalMemory() - freeMemory() 的值。
Heap Free: Native Heap 是 mallinfo() 里面 fordblks 的值,表示当前 native heap 空闲内存的大小。Dalvik Heap 是 Runtime 里面 freeMemory() 的值,表示虚拟机 heap 空闲内存大小。虚拟机 heap 的空闲内存小到一定程度会有一定程度的策略扩大 heap 的 total size,策略的阀值由上面说的属性控制。
(2). 接下来再说竖着的行:只有 Pss Total、Private Dirty、Private Clean、SwapPss Dirty 区分竖直的分类(Heap Size、Heap Alloc、Heap Free 只区分 Native Heap 和 Dalvik Heap 前面已经说过了)
Natvie Heap: /proc/pid/smaps 中: 所有 [heap]、[anon:libc_malloc] 的 vma 中各自字段之和。例如说 Natvie Heap 的 Pss Total 就是所有的 [heap]、[anon:libc_malloc] 的 vma 中 Pss 之和。从 vma 的名字来看,应该是 natvie malloc 申请的内存。
Dalvik Heap: /proc/pid/smaps 中所有以 [anon:dalvik-alloc space、[anon:dalvik-main space、[anon:dalvik-large object space、[anon:dalvik-free list large object space、[anon:dalvik-non moving space、[anon:dalvik-zygote space 开头的 vma 中各字段之和。从 vma 的名字来看,应该是 java 虚拟机申请的内存。
Dalvik Other: /proc/pid/smaps 中 vma 中一些以 anon:dalvik 开头的字段之和(大部分是除了上面 Dalvik Heap 之外的),有点多我就不一一列的,详细的可以自己去 android/framework/base/core/jni/android_os_Debug.cpp 里面的 load_maps() 函数里面看。这里看 vma 名字像是虚拟机的一些引用计数、字节码缓存之类的。
Stack: /proc/pid/smaps 中所有以 [stack 开头的 vma 各字段之和。应该是栈申请的内存,一般也不是很大,几十k这样。
Ashmem: /proc/pid/smaps 中所有以 /dev/ashmem 开头的 vma 各字段之和。应该是前面说的进程间的共享内存。
Other dev: /proc/pid/smaps 中所有以 /dev 开头的 vma 各字段之和。应该是一些设备驱动映射的内存。
.so mmap: /proc/pid/smaps 中所有以 .so 结尾的 vma 各字段之和。是 load so 映射的内存。
.jar mmap: /proc/pid/smaps 中所有以 .jar 结尾的 vma 各字段之和。是 load jar 映射的内存。
.apk mmap: /proc/pid/smaps 中所有以 .apk 结尾的 vma 各字段之和。是 load apk 映射的内存。
.ttf mmap: /proc/pid/smaps 中所有以 .ttf 结尾的 vma 各字段之和。是 load ttf 映射的内存。
.dex mmap: /proc/pid/smaps 中所有以 .odex、.dex、.vdex、结尾的 vma 各字段之和。应该是加载虚拟机字节码、预编译的字节码映射的内存。
.oat mmap: /proc/pid/smaps 中所有以 .oat 结尾的 vma 各字段之和。应该是加载虚拟机预编译字节码映射的内存。好像是 system 的 jar dex2oat 出来的是 oat,其他的是 odex。
.art mmap: /proc/pid/smaps 中所有以 .art、art] 结尾的 vma 各字段之和。这个好像是 odex 的一些索引,又叫启动镜像。也是虚拟机预编译出来的内容加载到内存里面所占用的。
Other mmap: 除了上面分类, vma 中有名字的各字段之和。
Unknown: 除了上面分类, vma 中没有名字的各字段之和。
Total: 分别等于各自列上的项目之和,Pss Total 还需要额外加上 SwapPss Dirty 这一列的求和。
(3).App Summary:
Java Heap: Dalvik Heap 的 Private Dirty + .art mmap 的 (Private Dirty + Private Clean)。Android 认为这些代表进程的虚拟机占用的内存。
Native Heap: Native Heap 中的 Private Dirty。Android 认为这个数值代表进程的 native 占用的内存。
Code: .so mmap、.jar mmap、.apk mmap、ttf mmap、.dex mmap、oat mmap 的 (Private Dirty + Private Clean )”。Android 认为这些是一些资源类(例如字节码文件、图片、字体等)占用的内存。
Stack: Stack 中 Private Dirty 的值。
Graphcis: 这个是 GPU 里面 texture、buffer 占用的内存,需要 gpu 驱动支持才行。0 的话代表 gpu 驱动还没支持。
Private Other: TOTAL(Private Dirty + Private Clean) - Java Heap - Native Heap - Code - Stack - Graphcis
System: TOTAL(Pss) - TOTAL(Private Dirty + Private Clean)
TOTAL: TOTAL(Pss)
TOTAL SWAP PSS: TOTAL(SwapPss Dirty)
(4).OBjects: 这些统计的是进程里面一些 Android Java 对象的引用信息,对于排查 Java 内存泄漏比较有用。这里不细说,其实看名字大概也能猜到是哪些对象。
(5).SQL: 应该是 sql 申请的内存,占时没研究过,不过一般这部分占用内存都不高。
procrank
procrank 是一个 native 的 bin 小工具,在 shell 中敲命令执行(在 userdebug 中 root 才能显示全,user 下会因为没权限,只能显示 total 数值。因为 shell 组没权限去读 /proc/pid/maps )。它的显示内容如下:
|
|
进程列表:
procrank 每个进程的内存信息是通过读取 /proc/pid/maps 统计的,这点和 dumpsys meminfo 不太一样(具体代码见: libmeminfo/procmeminfo.cpp 的 ReadMaps() 和 ReadVmaStats())。dumpsys meminfo 统计的进程的 Pss 是通过 /proc/pid/smaps 统计的,会比 procrank 的大一些,包含了 Zram 里面的 SwapPss。来看一下先说横着的列:
Vss(Virtual Set Size): /proc/pid/maps 中每一段 vma 的 size 之和。size 可以通过 vma 的 (结束地址 - 开始地址) x page_size 计算出来(一般 page_size 是 4kb,代码里面可以通过 unistd.h 里面的 getpagesize() 获取)。这里的 vma 有一些是没有映射到内存里面的(或者在 Swap 里面的),像是 page_count = 0 的就是没映射的,也就是没有被任何进程引用(注意和下面 Rss 的区别)。page_count 可以通过 /proc/pid/maps 中 vma 的虚拟地址,在 /proc/pid/pagemap 里面获取到内存页面的 PFN(Page Frame Number),然后再在 /proc/kpagecount 里就能读到页面被引用的计数了(具体的可以看 procrank 的源码或是参考资料里面的 pagemap 的相关资料)。再加上进程里面有很多共享库和资源(特别是 Android apk 是从 Zygote fork 出来的),所以 Vss 一般都很大,所以没啥参考价值。具体的怎么索引的和页面表的标志位含义可以看附录参考资料里面的 利用/proc/pid/pagemap将虚拟地址转换为物理地址 和 pagemap和VSS/USS/PSS/RSS的计算。
Rss(Resident Set Size): /proc/pid/maps 中 page_count > 0 的 vma size 之和。 和 Vss 相比, 多了page_count > 0 这个过滤,表示这段 vma 至少被一个进程引用(被映射到内存当中)。所以 Rss 表示进程实际占用内存的情况(包含共享资源)。
Pss(Proportional Set Size): /proc/pid/maps 中每一段 vma size / page_count 。和 Rss 相比,Pss 把多进程共享资源部分的内存按比例均分了。所以 Pss 表示进程实际占用内存的情况(共享资源按比例均分)。一般可以拿 Pss 来衡量进程内存占用情况。
Uss(Unique Set Size): /proc/pid/maps 中 page_count = 1 的 vma size 之和。和 Pss 相比,Uss 除去了共享资源的内存。所以 Uss 表示进程私有内存占用的情况。
Swap: 和 dumpsys meminfo 统计的类似,当开启了 Zram 就能统计到 Swap。这里的是通过 linux 的接口判断出 /proc/pid/maps 中哪些 vma 是在 Swap 分区里面的(同样是在上面的函数里面判断的)。这里统计到的值是包含了进程共享资源内存的 Swap 的,和 Vss 类似。
PSwap: 和 dumpsys meminfo 里面的 SwapPss 一样,按 page_count 均分了。和 Pss 类似。
USwap: Swap 里面 page_count = 1 的。和 Uss 类似。
ZSwap: PSwap x zram 压缩率。 zram 压缩率 = zram_size / (SwapTotal- SwapFree)。zram_size 是前面介绍的 /sys/block/zram0/mm_stat 第三个数值,SwapTotal 和 SwapFree 是 /proc/meminfo 下面的数值。
TOTAL: 上列表的简单求和。
ZRAM:
这里的 Zram 信息和 dumpsys meminfo 是一样的。
RAM:
这里信息都是直接从 /proc/info 下读取同名的数值(名字有点点差别)。另外 free+cached 的数值是我们平台自己加上去的。
/proc/pid/maps
每个进程都会有这个文件节点,表示进程的内存映射信息。例如说我们 cat 一下 systemui 的:
|
|
上面只是截图了前面一部分,因为是整个进程的内存页面,所以整个文件会比较大(和进程复杂度有关,systemui 挺复杂的)。里面每一行代表一个 vma(virtual memory areas:虚拟内存区域)。下面我们来看看 vma 每一列代表什么含义:
12c00000-12cc0000: 这个是该虚拟内存段的开始和结束地址。通过地址 x page_size 可以计算出该段内存的大小。
rw-p: 该段内存的权限。前3位分别是:读、写、执行,最后一位 p 代表私有,s 代表共享。
00000000: 该虚拟内存段起始地址在对应的映射文件中以页为单位的偏移量,对匿名映射,它等于0或者vm_start/PAGE_SIZE。
00:00: 文件的主设备号和次设备号。对匿名映射来说,因为没有文件在磁盘上,所以没有设备号,始终为00:00。对有名映射来说,是映射的文件所在设备的设备号。上面有映射号的都是一些文件资源。
0: 被映射到虚拟内存的文件的索引节点号,通过该节点可以找到对应的文件,对匿名映射来说,因为没有文件在磁盘上,所以没有节点号,始终为00:00。
[anon:dalvik-main space (region space)]: 被映射到虚拟内存的文件名称。后面带(deleted)的是内存数据,可以被销毁。对有名来说,是映射的文件名。对匿名映射来说,是此段虚拟内存在进程中的角色。dumpsys meminfo 是通过这个字段来进行分类统计的。
/proc/pid/smaps
smaps 是 map 的扩展,它显示的信息更加详细,还是拿 systemui 的来举例:
|
|
这里也是截图了其中2段 vma。
Size: vma 空间的大小。可以由地址计算出来。等于 Vss,进程有时候 malloc 了一大块内存,但是并没有真正使用。但是还是会计算这块内存的大小。
KernelPageSize: kernel page size 的大小,一般是 4kb。
MMUPageSize: MMU page size 大小,一般等于 KernelPageSize。
Rss: 前面解释了。
Pss: 前面也解释了。
Shared/Private: 该 vma 是私有的还是共享的。对照前面的权限标志位的最后一位,确实 p 的 Shared 有数值,并且不等于 Pss(被均分了);而 s 的就是 Private 的有数值,并等于 Pss(因为是私有的)。
Dirty/Clean: 在页面被淘汰的时候,就会把该脏页面回写到交换分区(换出,swap out)。有一个标志位用于表示页面是否dirty。
Referenced: 当前页面被标记为已引用或者包含匿名映射。
Anonymous: 匿名映射的物理内存,这部分内存不来自于文件的内存大小。
AnonHugePages 统计的是Transparent HugePages (THP)。我暂时没理解是啥意思(网上抄的说明)。
Shared/Private_Hugetlb: 由hugetlbfs页面支持的内存使用量,由于历史原因,该页面未计入“ RSS”或“ PSS”字段中。 并且这些没有包含在Shared/Private_Clean/Dirty 字段中。(网上抄的说明)。
Swap: 开启 Zram 后,Swap 到 Zram 分区的大小。这里是包含了共享资源部分内存的。
SwapPss: Swap 共享部分按比例均分。
Locked: 常驻物理内存的大小,这些页不会被换出。
VmFlags: 表示与特定虚拟内存区域关联的内核标志。标志如下:
|
|
/proc/meminfo
前面的 dumpsys meminfo 和 procrank 中 total 统计的部分的基础就来源于这个节点的数值:
|
|
选一些重点的讲一些:
(1).MemTotal: 总共系统可用的物理内存。你会发现这个并不等于实际贴在机器上的内存大小。是因为还有一部分内存要作为 linux kernel 的保留内存(reserved)。保留内存的详细信息后面再说。
(2).MemFree: 这个就是真正意义上没有被使用的内存了。这值在 linux 系统上会比较低,其实有一部分内存是各个进程正在使用的,还有一大部分是 Cached。linux 的设计本意就是尽量多的使用内存,来保证进程间切换的平滑性(多任务)。
(3).MemAvailable: 这个值会比 MemFree 多一些,kernel 根据一些可以回收的内存(例如 cached、buffer 之类的)估算出一个能用的。这个值我目前没发现有啥用处。
(4).Buffers: 块设备(block)申请的内存。
(5).Cached/Mapped/AnonPages: 进程的内存页面分为2种: file-backed pages(与文件对应的内存页)和 anonymous pages(匿名页)。file-backed pages 是指例如说进程的代码段、so、jar 库之类的,映射的都是 file-backed,而进程的堆、栈是不与文件相对应的,就属于匿名页。file-backed pages 在内存不足的时候可以直接写回硬盘的文件(叫 page-out),而不需要用到交互区(swap);而匿名页在内存不足的时候就只能写到硬盘的交换区里(叫 swap-out)。
AnonPages: 是前面提到的 anonymous pages。它是进程的私有堆栈。
Mapped: 是前面提到的 file-backed pages。
Cached: Cached 是 Mapped 的超集,除了包含 Mapped 之外,Cached 还包括了 unmapped 的页面。进程中的 file-backed pages 被 unmapped 后不会马上回收,而是当做缓冲计算在 Cached 当中。但是进程中的 anonymous pages 一旦进程退出,则会马上回收。
(6).SwapCached: 这个好像是 Swap 分区的 page cached。SwapCached 并没有包含在 Cached 里面。
(7).Active/Inactive/Active(anon)/Inactive(anon)/Active(file)/Inactive(file): linux kernel 有个 LRU 的页面回收算法。LRU list 包括:LRU_INACTIVE_ANON(Inactive(anon))、LRU_ACTIVE_ANON(Active(anon))、LRU_INACTIVE_FILE(Inactive(file))、 LRU_ACTIVE_FILE(Active(anon))、LRU_UNEVICTABLE(Unevictable)。Active 就是对应正在使用的内存页面,一般这种是无法回收的。而 Inactive 则是最近没在使用的页面,一般这种是可以回收(reclaimed)的。而 Active(anon/file)则分别代表了正在使用的 anonymous pages 和 file-backed pages。Inactive(anon/file) 则是最近没在使用的 anonymous pages 和 file-backed pages。从上面定义来看一般: Active(anon) + Inactive(anon) = AnonPages ,但是发现并不相等,一个会受 Shmem 状态的影响,一个是有点小偏差。同理 Active(file) + Inactive(flie) 与不完全等于 Cached,一个也是受 Shmem 状态影响,一个是 Activie(flie) + Inactivie(file) 还包含 Buffers。
(8).Unevictable: 是不能被 page-out/swap-out 的页面。
(9).SwapTotal/SwapFree: 前面说了,配置了 Zram 后,swap 分区的总大小和空闲大小。
(10).Shmem: 包括 shared memory 和 tmpfs。android 上一般也不大。
(11).Slab/SReclaimable/SUnreclaim: Slab 是 linux kernel 上的一种内存分配管理机制,一般是内核模块使用。SReclaimable 和 SUnreclaim 一个是可以回收的,一个是不能回收的 Slab 内存,而 Slab 则这2个加一起。dumpsys meminfo 把 SUnreclaim 算成是 kernel Used 。
(12).KernelStack: 前面有提到过,是内核的调用堆栈。内核栈是常驻内存的,既不包括在 LRU lists 里,也不包括在进程的 RSS/PSS 内存里,所以可以认为它是 kernel 消耗的内存。dumpsys meminfo 把 KernelStack 也计算在 Kernel Used 里面
(13).PageTables: Page Table用于将内存的虚拟地址翻译成物理地址,随着内存地址分配得越来越多,Page Table会增大。请把Page Table与Page Frame(页帧)区分开,物理内存的最小单位是 page frame,每个物理页对应一个描述符(struct page),在内核的引导阶段就会分配好、保存在 mem_map[] 数组中,mem_map[] 所占用的内存被统计在 dmesg 显示的 reserved (前面提到的 kernel 预留内存)中,/proc/meminfo 的 MemTotal 是不包含它们的。而Page Table的用途是翻译虚拟地址和物理地址,它是会动态变化的,要从 MemTotal 中消耗内存。dumpsys meminfo 把 PageTables 计算在 Kernel Used 里面。
(14).VmallocUsed: kernel 模块使用 vmalloc 申请的内存。它也是算 kernel 使用的内存的,dumpsys meminfo 把 VmallocUsed 也计算在 Kernel Used 里面。然而在 Android 上 /proc/meminfo 这里的 VmallocUsed 统计不到数值。dumpsys meminfo 是通过 /proc/vmallocinfo 统计的。/proc/vmallocinfo 里不仅有 vmalloc 的,还有 ioremap(这个是IO地址映射的)、vmap 的,这2个是不占内存的。vmalloc 的每一行有 “pages=x” 的页面数量信息,所以直接计算 pages 的总数,然后 x page_size 就能统计到 VmallocUsed 了(这也是前面 dumpsys meminfo kernel used 那里我说计算 pages= 的理由)。
(15).CmaTotal/CmaFree: 配置的 cma 总大小和 free 大小。一般有 iommu 的方案 cma 都会比较小。
其他一些数值不是很重要就不细说了。
PageMap
PageMap 是一个 github 上的小工具(github地址),可以统计到每个进程匿名页、文件缓存等信息。可以认为是 /proc/meminfo 的 pid 版本。它的源码也比较简单,就一个 PageMap.c 文件,统计的方法是:
(1). 遍历 /proc/pid/maps 中的所有 vma(也就是每一行)。
(2). 通过 vma 的虚拟地址在 /proc/pid/pagemap 里面找到对应的 PFN,这是一个 64 bit 的值,含义 kernel 说明文档如下:
|
|
(3). 通过 PFN 可以在 /proc/kpagecount 里面得到对应页面的引用计数。
(4). 通过 PFN 可以在 /proc/kpageflag 里得到对应页面的标志位,从而判断出页数的属性(这个标志也是个 64 位数值,可以通过位来判断),通过页面属性累计各种信息(例如匿名页、文件缓存等):
|
|
其实上面的过程和前面 procrank 统计 Vss/Rss/Pss 是类似的。但是这个工具跑在全志的平台上统计需要稍微改一下:
|
|
然后可以用编译服务器的 arm-gcc 编译:
|
|
编译出来的 bin 文件 push 到 /data/local/tmp/(chmod +x 加下执行权限),用下面就可以统计指定进程的详细信息了: /data/local/tmp/pgmap_my -v -p pid > /sdcard/pgmap.txt 。统计是打印信息,所以需要重定向到一个文本里面,而且是一个页面一个页面的信息,还需要脚本二次统计:
|
|
每个页面的页面属性(Flags 那里的),引用计数(RefCnt)会打印出来。例如说我们比较关心的就是进程的匿名页面和缓存信息,可以用下面脚本对得到的文本进行统计:
|
|
这个脚本需要 linux 环境运行(window 可以用 cygwin),也可以直接 push 到设备上跑: sh /data/local/tmp/x1.sh /sdcard/pgmap.txt :
|
|
ion
ion 是 google 推出的 Android 的一种内存管理机制,一般用于多媒体、Camera、显示模块。它可以在用户空间的进程间共享,或者内核的模块之间共享。我个人认为 ion 的内存没有计算在前面的进程内存里面(Pss)或者 kernel 模块里面(/proc/meminfo)。我们先来看一下 ion 的内存怎么看,Android 10 上面有一个节点可以看到: cat /sys/kernel/debug/ion/heaps/sys_user:
|
|
上面列出了所有进程(ion 的 client)申请的 ion 的情况(上面单位是 byte)。上面主要分为2部分:
(1). init 占用的。这里并不多,也就才 4M 左右。上面 pid 1 和 1397 分别是2个 init 进程(好像从 android 某个版本开始就有2个 init 进程了)。一般 init 申请 ion 是用来做一些平滑显示用的。
(2). 1938 从上面的进程列表可以看到是 android.hardware.graphics.allocator@2.0-service 。这个是 android 的里面的一个 hal 模块,用来管理 buffer queue 的(以前的 android 版本好像叫 gralloc)。procrank 可以看到这个进程就算是算 Rss 也才 4.8M,但是从 ion 这边看到的它申请的 ion 内存却有 23M。所以我认为前面计算进程 的 Pss 没有统计 ion。而且网上有个补丁:android: ion: include system heap size in proc/meminfo ,这么看原生的 /proc/meminfo 也是没统计 ion 的。gralloc 申请的 23M 内存大多数都是 SurfaceFlinger 用了,可以使用 dumpsys SurfaceFlinger 查看:
|
|
gralloc 的 23M 都是 SurfaceFlinger 的 BufferQueue。一个 BufferQueue 一般对应一个显示图层(Layer)。一般普通的 Layer 对应的 BufferQueue 是3重缓冲,所以有3块内存块(壁纸的好像有点特殊只有一个)。除了显示的 Layer 的 BufferQueue 之外,还有一个 FramebufferSurface 的 BufferQueue,这个是用来做 GPU 合成的。所以说显示的 Layer 越多,就越占内存(BufferQueue 越多),而且也越占带宽(无论是 GPU 合成还是 HWC 合成,多一个图层就多一次合成操作)。
Kernel used
目前我还是认可 dumpsys meminfo 中 kernel used 的统计方式:Shmem + SUnreclaim+ PageTables + KernelStack + VmallocUsed。
Kernel reserved
前面有说无论是 /proc/meminfo 还是 free 看到的可用内存都会比物理内存小。这其中差的内存就属于 Kernel reserved。这部分内存有一些是一些驱动专用内存,一些是内核代码段,一些是内存页表。有几种方法可以看到 reserved 的信息:
(1). 开机启动的 dmesg 打印(一般可以接串口打印看到):
|
|
(2). cat /sys/kernel/debug/memblock/reserved:
|
|
第一种方法看到的可用内存 476056K 会比 /proc/meminfo 的少一些。是因为这里统计的的可用内存有一部分在 boot 阶段还未释放,所以启动后的 /proc/meminfo 的可用内存会比这里统计的高一些。这里的一些内核代码段和init的一些占用,加起来也不等于后面的 40040K reserved,而且 reserved 也不光光只有这些。
所以还是第二种方法好一些,而且还能看到具体的地址分布。这个在优化 reserved 内存的时候相关负责的研发可以根据地址分布推断出是哪里占用 reserved 内存,从而进行裁剪、优化。第二种方法累积求和和第一种的 reserved 差不多(需要把最后那个 8192K 剪掉,这个是 cma 大小。cma 系统是可以使用的,不应该计算在 reserved 里面)。reserved(40025kb) + memoryTotal(486028kb) 会比 512Mb(例子中是 512 的样机) 大一点点,可能多多少少哪里又有点统计重复了。上面的注释是根据全志平台的 kernel 推断出来的。
MAT
MAT(MemoryAnalyzer)是一个分析 java heap 的工具,可以分析 java heap 中对象的引用情况。一般来说这个工具是用来分析 java 内存泄漏的,但是这个工具同时也可以拿来分析内存占用情况。我之前写过一篇 MAT 的使用文章可以参考一下:Android 应用内存泄漏问题分析
MAT 可以在官网下载到:MAT下载地址。使用方法就是抓取 dump heap 文件,让用 MAT 打开来分析。dump heap 可以使用 AndroidStudio 抓,也可以使用 sdk 里面的 monitor.bat 抓,但是我更喜欢用命令行抓:
|
|
MAT 打开 hprof 文件后,一般选 Top Consumers(占内存最高的对象和Class):
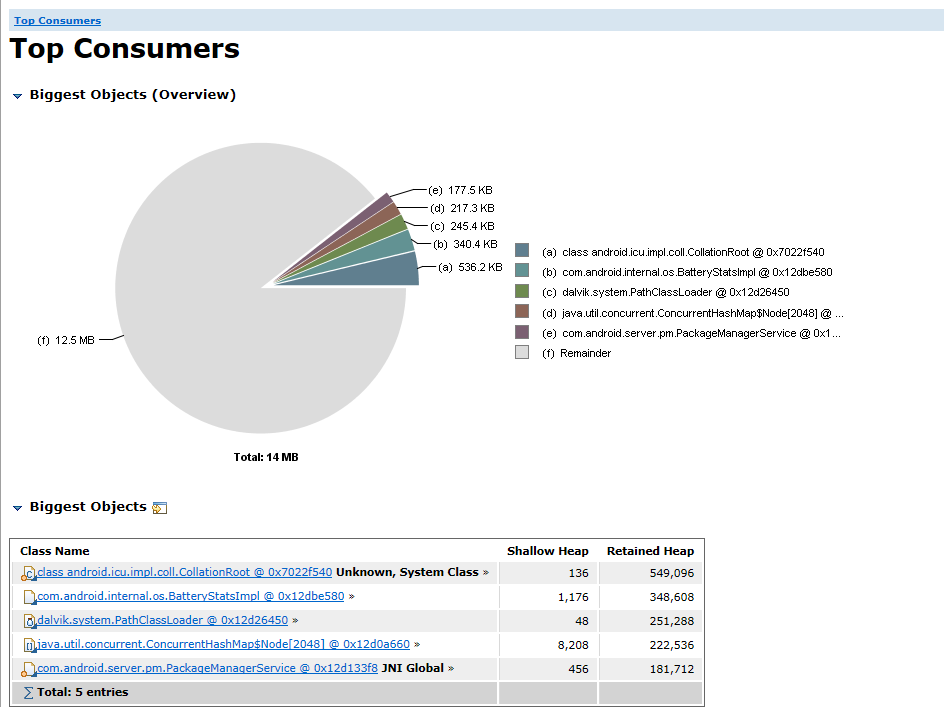
这张图显示的是 java 单个对象占用内存最高的排行榜(这里是 dump system_server 的)。从这里看到基本上没什么大的对象(一般来说像 Bitmap 这种就是大的对象),单个对象最大的也就才 500k。
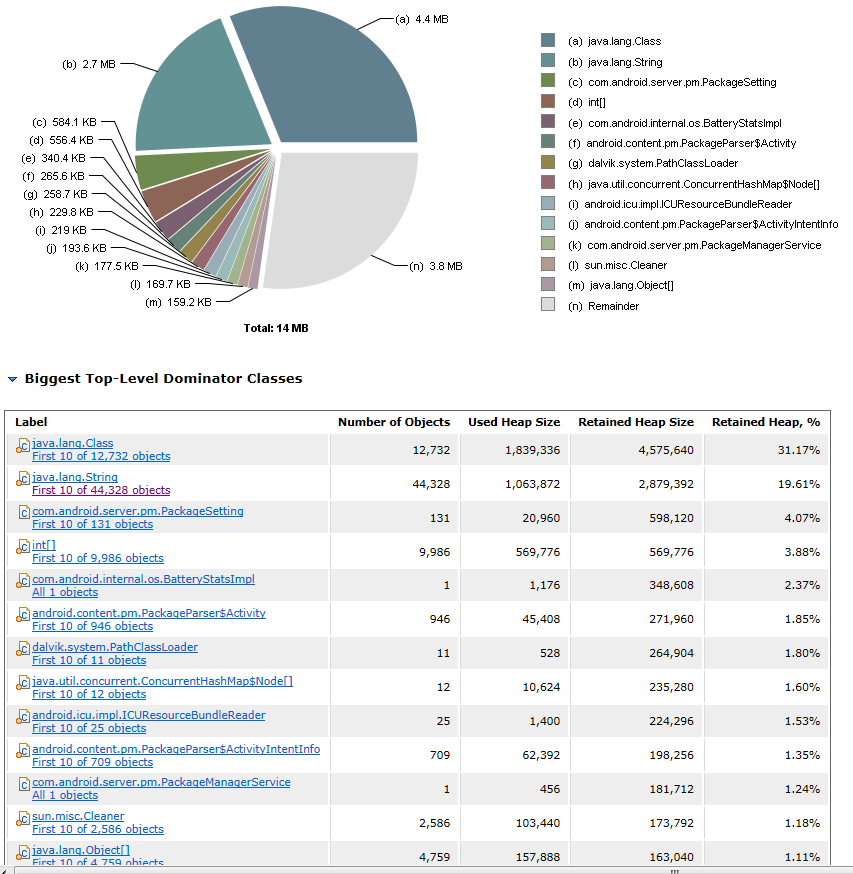
这行图是显示占内存最多的类的排行榜。从这里可以看到都是数量巨大小对象占了内存。所以不是很好简单的针对优化。例如说如果有 Bitmap 这种大对象的就可以看看是不是可以剪裁掉。这里结合 system_server 应该是里面包含了很多服务对象导致,可以考虑删掉一些不需要的服务模块来减少一部分对象,来节省一些内存。
malloc_debug
上一章的 MAT 是分析 java 内存的,这一章介绍的 malloc_debug 就是分析 native 内存的。它是 libc 的一个调试开关,打开之后 c 库会跟踪并记录每一个 malloc 的调用堆栈。下面是它的源码和说明:
android/bionic/libc/malloc_debug
android/bionic/libc/malloc_debug/README.md
调试普通 app 和 platform apk 是不太一样的,这里我们介绍 platform apk 的调试方法,因为我们这里是用来分析内存占用的。这个工具又分为:
(1).中途抓取: 让应用先启动,然后发送一个信号量打开 malloc_debug 开关。这个适用于排查一些内存泄漏场景,并不适合我们这里分析系统模块的内存占用情况。
(2).从开始抓取: 这个需要先把 malloc_debug 打开,然后再让应用运行,这样就能完整的记录下来每一个 native 的 malloc 申请,这样才能分析内存占用情况。
所以我们这里介绍的是基于 platform apk 从头开始抓取的用法(注意这里需要使用 userdebug 或是 eng 固件,user 固件是无法调试的):
|
|
这里说明一下:让 app_process(zygote) 开启了 malloc_debug ,也就是让所有的 apk 进程开启了 malloc_debug ,这会导致 system_server 启动变得很慢,很容易造成卡死,然后触发 WatchDog 自动重启,导致抓取失败。有几个方面可以改善一下:
(1). 尽量选择内存大的机器来抓取,这个并不影响分析结果的。因为记录每一个 malloc 的堆栈,会额外占用内存。最少1G以上的,512M 的就不要抓取了,基本无法启动。
(2). 所以上面 backtrace 配置成 8,默认的 16 更加难以成功启动。
(3). 注意观看 logcat,如果有报由于什么卡住了导致重启,就先把这个相关的功能先注释掉(例如说开启了 malloc_debug ,awbms 老是报错,我就先把 awbms 注释掉了)。
然后剩下的就是靠运气了不停的重试了,我在 A50 Android10 1G 的设备有一次成功启动了。启动了之后使用下面命令在抓取:
|
|
dumpheap -n 出来的 txt 就已经包含了每个 malloc 的调用堆栈,但是都是一些函数地址,需要自己去 maps 文件的代码段,去符号表里用 addr2line 反编译来看。这里就不介绍具体方法了(网上也有),sdk 里面这个 python 脚本就是帮我们转化了(所以他也是需要符号表的)。例如说转化出来的一个报表是(抓的是 Android 10 systemui 的):
|
|
点开 app 开具体情况,zygote 的是父进程的:
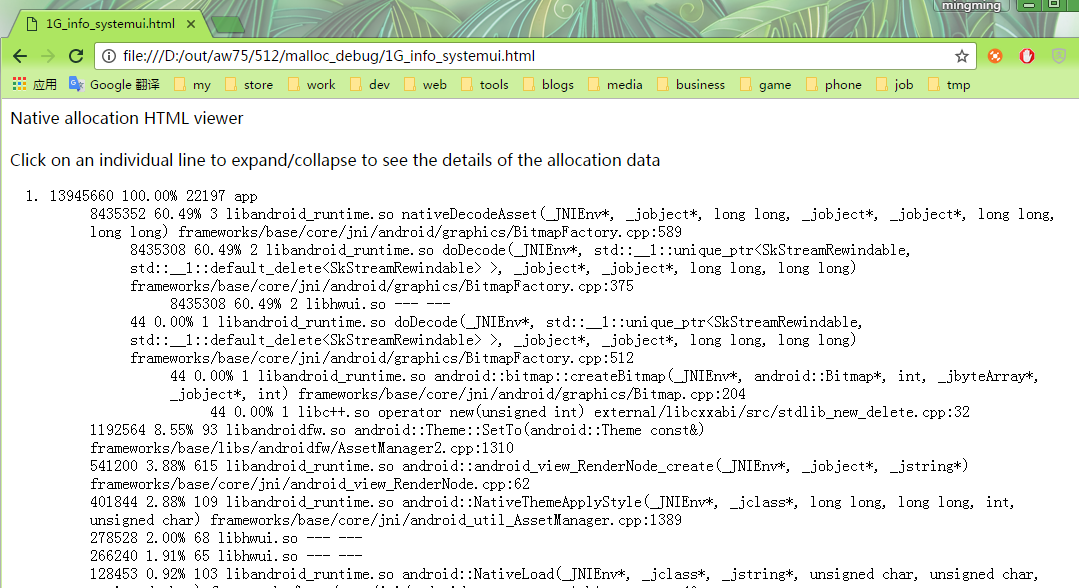
systemui 的 native 堆栈一共 13.2MB(13945660 单位是字节)。下面的对象是按占用内存大小来排序的。排在第一个是一个 8MB 的 Bitmap decode 的时候申请的,占了 native heap 60% 的大小。这里我把堆栈配成了8,好像不是很直观的看到是哪里调用到的。但是 systemui 里面 8M 大小的 Bitmap,之前 dumpsys SurfaceFlinger 的时候看到 ImageWallpaper 申请的 Layer buffer 刚好是 8M。所以可以猜想到这个应该是 ImageWallpaper 加载的 Bitmap 申请的内存。然后去查看了一下相关代码,正是 SystemUI load ImageWallpaper 的 Bitmap 申请的内存。所以一张壁纸不光占用了显示 buffer(图层),同时加载的 Bitmap 也很占内存。如果不要壁纸的话,把图层和 Bitmap 都干掉,这里以 A50 Android10 1280x720 为例,可以节省 16M 的内存。
工具小结
内存总计
上面说了那么多,我们试着来看看统计一下系统各个模块内存的占用情况。我以上面的列举的数据为例:样机物理内存 512Mb,减去大概 40Mb 的 reserved,系统可用内存为: 486028 Kb。根据上面的理论知识,系统总共内存应该等于下面各个部分之和:
(1). 所有进程的 Pss 之和:可使用 dumpsys meminfo 的中的统计。但是这个是包含了 Zram SwapPss 的,如果用这个,那应该减去 SwapPss 的部分(我认为可以使用 ZRAM 里面的 68,664K in swap - 22,368K physical used)。如果使用 procrank 的 Pss 统计之和,这个是不包含 SwapPss 的,所以应该把 Zram 22368K physical used 这部分加上。
(2). 缓存中 unmapp 的部分:这部分没有统计在进程 Pss 里面,可以使用 /proc/meminfo: Cached - Mapped
(3). 空闲内存:/proc/meminfo: free。
(4). Kernel Used:可以按照 dumpsys meminfo 的统计。
(5). Kernel Cached:也可以按照 dumpsys meminfo 的统计,但是这个计算公式把 (2) 那里也算上了。
(6). gralloc 申请的:前面有统计方法。
(7). cma:前面有统计方法。
其实仔细看上面这些部分,可以等效等于 dumpsys meminfo 中的 Free RAM + Used RAM - SwapPss + gralloc + cma。按这个计算:
168,297K + 292,956K - (68,664K - 22,368K) + (29347840 / 1024)K + 8192K = 451809Kb
和系统记录的 486028 kb 还有点差距。可能是哪里统计有漏洞(我也没一一去看统计代码,网上一些资料说这些统计是点有遗漏的),也有可能是例子这个样机还没支持 dumpsys meminfo GL(A50 Android 10),GPU 那部分内存没统计上(也不确定 GPU 驱动的是不是包含在哪个里面了)。然后其实进程 Pss 之和还可以用 procrank 的,前面也有说,再加上 Zram physical used 的。然后其他的内容去 /proc/meminfo 里面自己算。计算出来的结果和上面直接加 dumpsys meminfo 的差不多。那目前来说我感觉这样也挺接近可用内存了。
然后我去拿了一台支持 dumpsys meminfo GL 的样机(A100 Android 10),通过上面的计算公式计算,发现已经和可用内存很接近了:
|
|
239,195K + 728,265K - (50,128K - 11,908K) + (41689088/1024)K + 8192K = 978144Kb
我拿的 oppo X20(4G,Android 8.1)也试了下,发现也挺接近了的(cat ion 没权限,可以用 dumpsys SurfaceFlinger 代替,在没有多媒体播放或是 camera 的情况下,误差不会特别大)。那应该这个计算方式还算靠谱吧。
应用内存分析
上面 dumpsys meminfo 还是 procrank 看到的 apk 进程占用的 Pss 都挺大的,但是其实单独 dumpsys meminfo pid 就会发现一般进程大部分都是一些文件缓存占用比较大(例如 Code、资源、库文件等)。可以单独看 Dalvik Heap 和 Native Heap,然后还能通过 MAT 和 malloc_debug 进一步分析是是哪些对象申请了内存。MAT 抓出来的 java heap 和 dumpsys meminfo pid 里面的 Dalvik Heap 中的 heap size 算是比较接近,但是还是有些差距,可能统计的内容有点不一样。malloc_debug 抓出来的 native heap 和 dumpsys meminfo pid 里面的 Native Heap 的 Total Pss 还是挺接近的,比 MAT 的误差小很多。
某些时候还能直接使用 /proc/pid/maps 或是 /proc/pid/smaps 直接分析,也可以使用 PageMap 具体查看应用的匿名内存页和文件缓存页情况。
优化思路
Kernel
Kernel used
按第一章的 kernel used 拆分,目前我的认知来说:
(1). 可以优化 Slab 的占用
(2). 可以去掉一些无用的,但是却加载了的 ko 模块
不过这个需要 kernel 的同事来分析,目前暂时还没接触到案例。以后接触到再补充。
Kernel reserved
kernel reserved 的大小直接决定了开机后 MemTotal 的大小。从第一章的拆分来看:
(1).精简代码段: 可通过 kernel 的 config 去掉一些无用的模块,这样可以节省一部分 kernel 代码段的占用。一般也是需要 kernel 的同事进行确认。例如说 R818 Android 10 1G 方案通过 menuconfig 去掉无用模块,代码段节省了 2M。
(2).删除 optee 部分内容: 这里就是第一章分析的 atf 那部分。如果是非安全系统,是几乎可以把整个 atf 部分删掉的(好像需要留1、2M吧)。如果是安全系统,那么根据需求可以删去一部分,例如说 R818 Android 10 1G 方案就删掉了 gatekeeper 和 keymaster(具体删掉方案得找相关负责人弄),atf 部分节省了 14M。
快速回收
这个是在研究竞品系统上发现的一个方法,原理是快速(强制)让 kernel 回收后台应用的匿名页面(anon)和文件缓存(file),从而达到增大 free+cache 的目的。kernel 原生有个 /proc/sys/vm/drop_caches 接口(echo 1 是释放 cache,echo 2 是释放 slab,echo 3 = 1+2),但是效果不是特别明显(很多占用的 cache 其实释放不掉)。kernel 同事仿造这个思路在 5.4 的 kernel 新增了一个接口(目前还处于调试阶段,我提前拿到补丁在平板上试了一下):/proc/sys/vm/reclaim ,用法如下:
|
|
在平板上以切换到后台的 Settings 为例,效果如下:
|
|
使用 echo 3 进行强制 anon + file 回收后:
|
|
可以看到强制回收后,在后台 Settings 的 Pss 大量减少,通过 PageMap 看到匿名页面和缓存页面大量被换入 Swap 分区。如果对所有后台进程都进行这个操作,那么 free+cache 将会大量增加(经过测试 512M 方案大概可以增加 40-50M)。
但是这个方案也是有弊端的,因为它的是通过牺牲了后台进程的缓存,来换取前台进程的可用内存。当再次切换到后台进程的时候经过强制回收后的进程,Activity 速度明显慢了一个档次。在平板上将 Settings 切换到后台,对比正常温启动和强制回收后的温启动2次启动的时间:
|
|
可以看到,强制回收后,由于失去了缓存的作用,温启动速度大幅度慢于正常的温启动。所以这方案仅适用于内存十分低下的设备(例如说 512)。io 很慢的 nand 设备也要慎用,因为强制回收后,不光是要从 Swap 解压内存,某些还是需要重新从磁盘 load 数据的,这会进一步放大 nand 设备 io 瓶颈问题。
Android
删除无用模块
这个是最简单,也是最有效的优化手段。随着 Android 版本的更新,功能增多和模块框架化的同时,进程会越来越多和臃肿。用 dumpsys meminfo 看看,结合具体产品看看,哪些 Pss 大,又用不到的模块就可以想办法删掉。其中有不少的模块都是可以直接删掉的,有一些可能需要改改代码,这个需要具体模块具体分析。在 R818 Android10 1G 方案上我列了一个表,删掉了 68 个 模块(有很多是主题 Overlay 只是能省一点 emmc 而已,并不能省运行内存)。删模块的时候最好一个一个的删,删除之后测试一下一些产品的基本功能是否正常,再进行下一个会比较好。
删一些系统自带的模块,可能无法避免要去修改 build/core 下面系统的编译脚本,这里介绍一个办法,可以巧妙的删除系统自带模块,而又不用修改系统编译脚本:
Android 的 .mk 文件里面有一个 LOCAL_OVERRIDES_PACKAGES 的配置,就是可以用当前的模块覆盖已有的模块。我们只需要在 vendor 下面新建一个空壳的模块(例如说 apk),然后把想要删除的原生模块给 override 掉就变相把这些原生模块给删掉了。例如说空壳 .mk 可以这样写:
|
|
其中 GLOBAL_REMOVED_PACKAGES 就是我们自定义的全局变量,可以在方案的 .mk 中配置这个变量,把想要删除的原生模块加到这个变量里面,例如说下面就是 R818 Android 10 1G 方案配置删除的原生模块:
|
|
精简模块内容
(1). 可以参看 1.10 和 1.11 小结的内容,找到模块中最占资源的内容,看看是不是可以精简掉。例如说在某些产品上精简掉不必要的壁纸,就能节省不少内存(同时去掉显示 Layer 和加载的 Bitmap)。如果说实在要保留壁纸,也可以限制壁纸的大小,让其不超过屏幕的大小,也能节省一些内存。
(2). 可以参考 Android Watch 的一些宏定义,精简 SystemService 一些不需要的服务,可以减少 SystemService 的一些占用。还可以去掉 Class 预加载,但是这个会减慢应用启动速度。
后续有什么新发现,再补充。
资源瘦身
例如一些 ttf 字体和 apk 的体积,应该可以减少 file cache 的占用。虽然 file cache 也可以算上可用内存,但是多余的资源占用的 file cache 还是比不上 free 内存好。这部分占时还没怎么研究,不太清楚效果,只是根据前面的理论分析得出一个思路。
待补充。
虚拟机参数调优
待补充。
lmk 参数调优
待补充。
多媒体
在低内存方案如何在解码一些大分辨率、高帧率视频,可能会存在解码器占用内存过多的情况。这个时候可以适当的降低一些解码器的 buffer 数量来减少内存占用。但是好像会稍微降低视频的平滑度。例如说之前 H313 512M 方案预研的时候曾经将 vbv buffer 调整了8M,去掉降噪模块,减少3个 framebuffer。这个具体需要多媒体的同事来分析、优化。而且这个优化只针对视频播放场景(解码场景),不过我们的产品关键场景就是视频播放。
参考资料
(1). dumpsys meminfo 源码(Android 10): android/frameworks/services/core/java/com/android/server/am/ActivityManagerService.java: dumpApplicationMemoryUsage()
(2). dumpsys meminfo pid 源码(Android 10): android/frameworks/base/core/java/android/app/ActivityThread.java: dumpMemInfoTable()
(3). procrank 源码(Android 10): android/system/core/libmeminfo/tools/procrank.cpp
(4). /PROC/MEMINFO之谜
(5).Kernel Zram 说明
(6).Android Zram 说明
(7).zram 简介
(8).Android 进程内存分配说明
(9).Linux内存管理 — /proc/{pid}/smaps讲解
(10).利用/proc/pid/pagemap将虚拟地址转换为物理地址
(11).pagemap和VSS/USS/PSS/RSS的计算
(12).PageMap统计工具GitHub